




Edge computing the future in computation

Currently, due to the technological development produced in the last years, the use of Internet Of Things (IoT) devices has expanded to multiple areas of daily life and there are few tasks that do not make use of this type of devices. Therefore, the amount of data that have been produced and sent to the data centers for further analysis has increased considerably, even reaching the limit of the network bandwidth requirements, in turn causing an increase in latency. In critical environments, such as a hospital o a manufacturing plant, where it is necessary to monitor certain processes in real time, the increase in latency is a serious problem that, in the worst cases, could result in large economic and human costs.
To deal with this problem, the paradigm known as Edge Computing was born, based on the idea of analyzing and processing data in the physical location (or close to it) where it has been collected. In this way, traffic is released to the data center and the results obtained are more reliable and faster.
An example of the application of this paradigm in everyday life can be found in the autonomous vehicles. This means of transport are currently equipped with lots of sensors and cameras that collect information, both on the state of the vehicle and the environment around it, and then, analyze the data collected and make decision in real time. The amount of data processed, and the network bandwidth required is huge, so it would be unfeasible to make use of other computing paradigms, such as Cloud Computing, cause that computing paradigms are based on processing the information in a remote center, completely distant from the IoT device (in this case the vehicle).
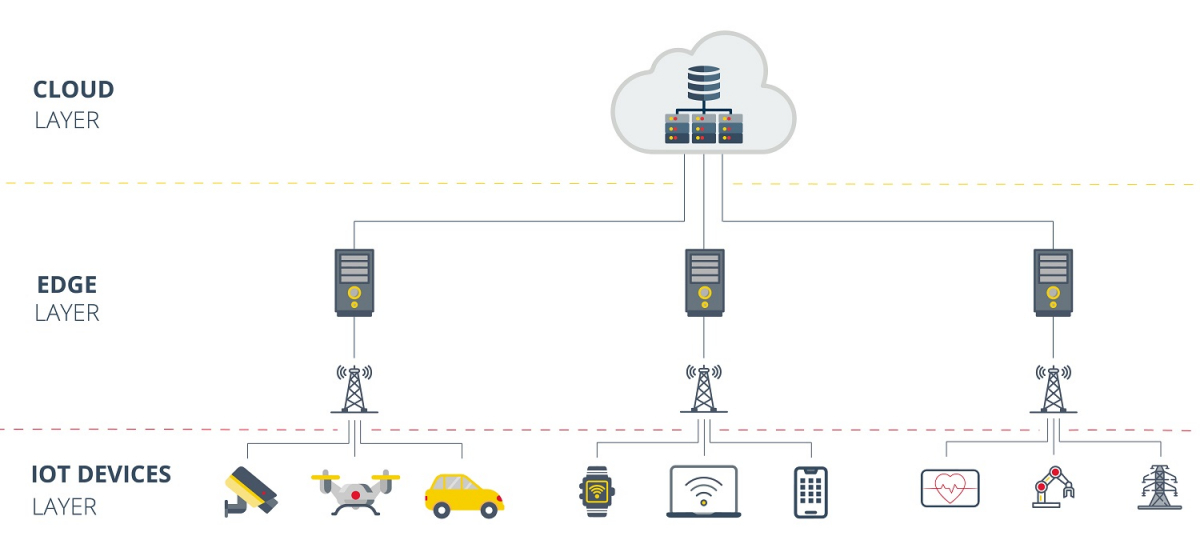
- Edge Computing layers -
Edge computing in the industrial world
One of the sectors where Edge Computing may become more important is in the industrial world, since the OT space is undergoing a revolution with the emergence of new intelligent hardware devices, together with software that treats and takes advantage of this intelligence. This, coupled with the importance of the latency in the processes and in the communication within a factory, makes the use of Edge Computing in OT seem inevitable.
One approach of how to implement Edge Computing in manufacturing plant would be by placing several Edge servers that aggregate and analyze information from IoT devices that are in groups. This clustering can be done in two different ways:
- Zone grouping: Each Edge server takes care of all the IoT devices in a particular zone, regardless of the type of device and the data that it generates. This clustering method is the most efficient, although is the most expensive due to the complexity of the server, which must be able to interpret and analyze data coming from different types of devices.
- Grouping by type: In this case, Edge servers are designed to interpret data from a particular type of device, so at least as many servers are deployed in a factory as there are different types of IoT devices in the plant. This solution generates more traffic and could crash the network if is not implemented correctly, but it is at least less expensive and does not require such complex servers.
However, each case is particular and the method and the manner in which the paradigm is applied may vary significantly. The following are the points to consider if it has been considered the implementation of Edge Computing:
- Device intelligence: The more intelligence an IoT device contains, the less intelligence will be necessary in the Edge servers. This is because, in this way, the data is filtered at the source and, therefore, the volume and format of the data is easier for the server to handle. However, the cost of the devices with a high level of intelligence is very high and, in many cases, is too large an investment, so it is recommended to seek a balanced level of intelligence between the IoT devices and the Edge server.
- Expected results: In order to identify exceptions, the false positives and outliers that maybe be generated and IoT device, it is necessary to collect data from multiple devices of same type and compare them with each other. This information is useful when generating rules in the in the Edge server and detecting anomalies in processes.
- Hub-and-spoke approach: The communication between different Edge servers can consume a lot of bandwidth collapsing the network easily. To avoid this, the hub-and-spoke approach is a good alternative. The main objective of this approach is to optimize the transport topology by using a central node as a logistic hub, for example: To communicate with the peripheral nodes. In this way, the plant´s Edge servers will transmit the information to a central server with greater computing capacity and a higher level of intelligence that will help analyze the data and make better decisions.
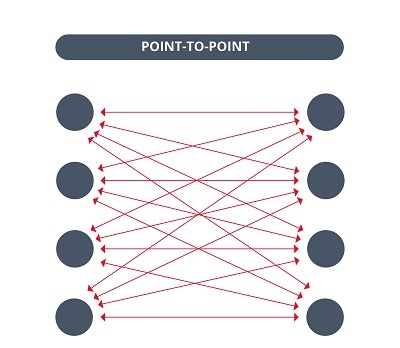
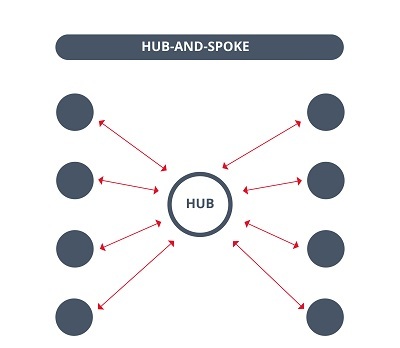
- Differences between Point-to-Point communications and hub-and-spoke communications -
- Advanced data analysis and reporting: Although automation has come a long way in recent years, it is still not 100% effective and there are certain task and decision that must be performed by humans. In these cases, Edge servers must be able to alert employees about the actions to be executed, in clear and intuitive way, to avoid confusion and worsen the situation.
Pros and cons
So far, the concept of Edge Computing and its growing implementation in the OT worlds has been introduced, but, like all other computing paradigm, its not perfect and has both positive and negative aspects that should be taken into account when making decisions about the manufacturing plant infrastructure.
In the next part of this section, the advantages why Edge Computing it is starting to be consolidated as the computing paradigm par excellence and why is the most suitable for a OT environment are described:
- Security: Unlike all other computing paradigms, Edge Computing distributes processing and storage capacity among the different Edge servers, allowing for a closed and modular solution that makes it difficult for attackers to both alter and compromise the data.
- Performance: One of the main reasons for the success of Edge Computing is its performance, since it achieves minimum latencies, thus facilitating the performance of tasks that are processed in real time. In addition, bandwidth consume is reduced so that bandwidth saved can be used for other types of services.
- Scalability: Once and Edge Computing based architecture is implemented, its subsequent upgrades and expansions are less costly because only the combination of IoT devices and local Edge servers need to be managed.
On the other hand, implementing an Edge Computing based architecture is not so simple, as it has certain disadvantages to consider that could hinder the process:
- Cost: To properly implement Edge Computing, IoT devices must contain a certain level of intelligence, and, in many cases, this means replacing existing devices with completely new and more expensive ones.
- Technical complexity: A distributed system, such as Edge Computing, is more complex than a centralize one, since the coordination and communication between the different serves / modules comes into play, which requires a high level of organization and management in order to obtain the maximum potential of the paradigm.
Conclusion
With the recent increase in IoT devices due to technological advancement, Edge Computing is here to stay, and more and more companies and industries are considering modifying their infrastructure to adapt to this computing paradigm.
However, although Edge Computing is the future of computing in the OT world, it is a change that many companies cannot yet afford, due to the difficulty of implementation. In these cases, do not rush, and it is advisable to plan a long-term strategy to adapt the current infrastructure to a more modern one that makes better use of IoT devices.
In short, Edge Computing is an excellent solution for processing immense amounts of local data in real time, thus optimizing critical processes that require minimum latencies and minimizing the use of network resources.





