





Machine learning en SCI

Pese a que los SCI han estado aislados de Internet durante mucho tiempo, los múltiples beneficios alcanzables para un negocio derivados de una convergencia entre SCI e Internet, así como con redes TI y la computación en la nube, han acelerado dicho proceso de integración. Como consecuencia, los SCI están cada vez más expuestos a los vectores de ataque usados en la mayoría de ciberataques, con el agravante de que estos sistemas son menos seguros que los sistemas de TI y, al mismo tiempo, mucho más críticos, tanto para las personas como para los negocios.
Desde el descubrimiento de Stuxnet se ha prestado mucha más atención al malware enfocado a PLC y otros sistemas industriales, que es capaz de averiguar la estructura física de una planta, lo que podría ser aprovechado por un atacante para alcanzar sus objetivos. Con el fin de hacer frente a este tipo de situaciones, existe una tendencia hacia la implementación de técnicas de machine learning para la detección de anomalías y prevención de ataques en las redes TO.
¿Qué es el machine learning?
El concepto de machine learning hace referencia a un método de programación de un sistema o aplicación orientado a la toma de decisiones, clasificación de sucesos o generación de información nueva de manera completamente autónoma. Todo ello en base a unos elementos de entrada, como puede ser información provista por los sistemas y redes que están siendo monitorizados.
La estructura algorítmica que más está dando que hablar en el ámbito de la inteligencia artificial es la estructura neuronal, más conocida como red neuronal, una arquitectura que imita la operatoria de las neuronas cerebrales. Su inteligencia se apoya en el entrenamiento. En cada iteración, la red da una respuesta en base a una entrada que posteriormente es comparada con una referencia. De esta manera, midiendo el error entre su respuesta y la real, la red es capaz de ajustar sus conexiones para dar una mejor respuesta en cada iteración. Los algoritmos con los que se entrenan estas redes pueden clasificarse en varios tipos:
- Supervisados (todos los datos de entrenamiento etiquetados): requieren de un humano para proveer a la red de los datos de entrenamiento (correspondencias entradas-salidas). En este grupo entrarían muchos de los clasificadores existentes, como los detectores de spam, árboles de decisión, clasificación de Naïve Bayes, regresión por mínimos cuadrados, Support Vector Machines (SVM)... Este tipo de algoritmo se utiliza en problemas de clasificación (identificación de dígitos, detección de fraude de identidad, diagnósticos…) y de regresión (predicciones meteorológicas, expectativa de vida, de crecimiento…).
- No supervisados (sin datos de entrenamiento etiquetados): la propia red es la que descubre cuándo se ha equivocado y aprende en consecuencia, sin necesidad de alguien externo que le muestre los datos de entrenamiento. Se suele utilizar en segmentación del tipo de usuarios y en las recomendaciones de consumo, puesto que es más sencillo discernir distintos patrones, problemas de clustering o análisis de componentes independientes (independent component analysis).
- Semisupervisados: se proporciona una mezcla entre correspondencias entradas-salidas y entradas sin su correspondiente salida. Utilizados principalmente cuando no se dispone de todas las correspondencias, sino que se dispone de una pequeña cantidad de datos etiquetados junto a una gran cantidad de datos no etiquetados. Este método de aprendizaje es muy útil en situaciones en las que es inviable etiquetar todas las muestras de entrenamiento, ya sea por su cantidad o por su complejidad, por lo que se etiquetan unas pocas y el resto se deja a criterio de la red neuronal.
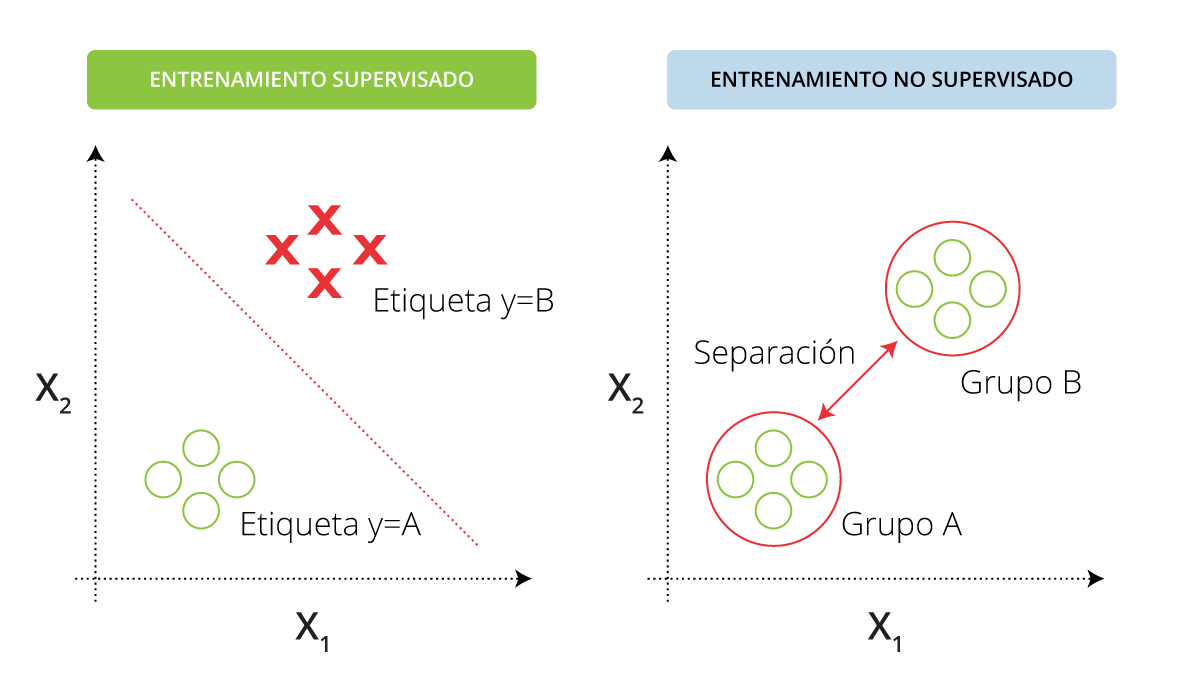
Figura 1: Clasificación de muestras según el tipo de entrenamiento. Fuente: ResearchGate.
Aplicaciones en ciberseguridad de SCI
Los sistemas y redes SCI son muy deterministas, es decir, presentan patrones de comunicación muy regulares. Suelen ser siempre el mismo set de comandos de escritura y lectura de variables de los registros, repetidos en el ciclo SCAN.
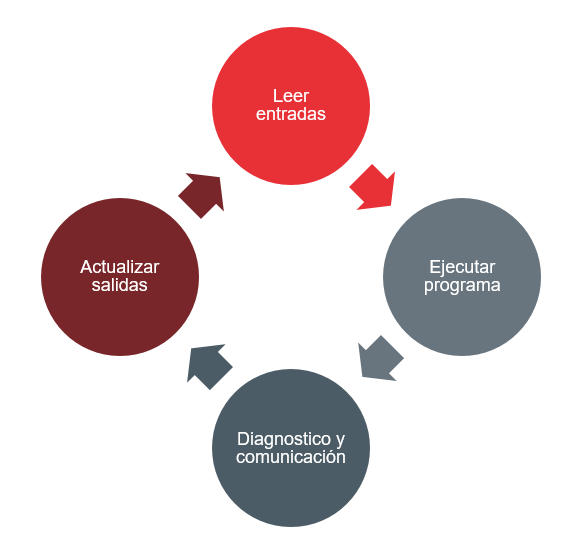
Figura 2: Diagrama del ciclo SCAN realizado por los PLC en su operativa.
Toda esta regularidad puede ser utilizada por una IA (Inteligencia Artificial) para establecer un estado “normal” de la red o sistema y monitorizar el tráfico y las configuraciones, comparándolas contra dicho estado.
Esta es la base para varias vertientes de investigación que se han ido realizando en los últimos años con relación al machine learning aplicado a la ciberseguridad en SCI. Entre estas se encuentran:
- Estrategias de seguridad para sistemas SCADA.
- Potenciar las funcionalidades de un SIEM implementando IA.
- Implementación de IDS (Intrusion Detection System) en SCI basados en inteligencia artificial.
- Creación de bases de datos estándares para el entrenamiento de estos algoritmos.
Centrándose en los IDS, hoy en día muchos de ellos emplean algoritmos de machine learning para el reconocimiento de patrones con el fin de detectar actividades anómalas en un sistema particular, sin embargo, no es el único método existente. En el artículo Intrusion Detection via Machine Learning for SCADA System Protection, se presenta un método de detección de intrusiones en un sistema SCADA basado en firmas digitales utilizadas para comparar actividades de determinados roles contra una base de datos de amenazas conocidas. Estos dos métodos podrían combinarse para crear un sistema de detección robusto y así proveer una capa de protección suficiente para varios escenarios de ataque.
En cuanto a los campos de aplicación, cabe destacar que otros sistemas IDS basados en machine learning han sido probados en un gran número de sectores de SCI, como en sistemas de distribución de agua, diagnóstico de turbinas de viento y en la detección de perturbaciones en los sistemas de suministro de energía.
Añadiendo valor a los sistemas actuales: ventajas y dificultades
Tal y como se ha comentado anteriormente, el machine learning tiene un gran potencial para mejorar los sistemas IDS/IPS (Intrusion Prevention System) actualmente existentes, dotándolos de mayor inteligencia, o incluso para sustituirlos.
Una de las principales ventajas de implementar soluciones basadas en IA para seguridad en SCI es la respuesta y actuación en tiempo real. Las herramientas basadas en machine learning no necesitan esperar a que el personal de seguridad tome decisiones ante incidentes. Estos son capaces de detectar intercambios de información anormales e inmediatamente responder a la amenaza, mucho antes de que un recurso SOC (Security Operations Center) haya sido alertado de la anomalía.
También cabe destacar la precisión que aportan estos sistemas a los ya existentes, reduciendo en gran medida los errores en las detecciones, siempre y cuando se utilicen modelos estables y los datos de entrenamiento sean lo más diversos posible.
Además, según este estudio, se ha observado que estos métodos son capaces de proveer información de seguridad importante para varios problemas físicos y situaciones prácticas. Sus autores sostienen que las soluciones basadas en machine learning son más sistemáticas, fáciles de manipular y gestionar.
Sin embargo, como en todas las aplicaciones basadas en estos algoritmos, todo esto solo es posible si se dispone de una buena referencia sobre cómo debe operar la red en situaciones normales, algoritmos de clasificación sólidos y acceso al mayor número de datos posible. De esta manera, el funcionamiento del algoritmo convergerá más rápidamente y de forma más estable, lo que dará como resultado un menor número de falsas alarmas y por ende una capacidad de detección de mayor calidad.
Pese a la popularidad de estos algoritmos, los grupos de investigación detrás del desarrollo de sistemas IDS carecen de bases de datos estándar para poder entrenar y evaluar sus algoritmos. Esto resulta en una incapacidad para desarrollar modelos de machine learning robustos para detectar anomalías en SCI. Muchas de las bases de datos ya existentes, especialmente contextualizadas en redes TO, no contienen todos los tipos de ataques, por lo que medir el rendimiento y capacidad de detección de un IDS resulta complicado.
Finalmente, cabe destacar que la implementación de buenos algoritmos para este fin está resultando ser bastante compleja, y su efectividad dependerá en gran medida de cómo de acotada esté la red a monitorizar y del nivel de determinismo que presente la información que se puede extraer de ella.
Conclusiones
Es indudable que el número de ciberamenazas en SCI, así como su complejidad, está aumentando de forma significativa año tras año. Por ello, es importante que los avances tecnológicos acompañen este crecimiento tratando de mejorar las contramedidas que son aplicables en la actualidad. El machine learning es un prometedor ejemplo de esto, presentando claras ventajas frente a los sistemas ya existentes. Sin embargo, para que pueda resultar efectivo en el mayor número posible de casos de uso del sector industrial, es necesario que se realicen mayores avances en este campo.





