





¿Qué es una correlación? … y herramientas de análisis de datos

Cuando se realiza un análisis de información, sobre un «conjunto de datos» (denominado «dataset»), cuyo origen («feed») puede ser bien una base de datos, como sobre archivos raw, logs, datos en hojas de cálculo etc. una de las herramientas más potentes para poder extraer conclusiones es realizar correlaciones.
Redundando en lo que ya se comentó en el post «La importancia del lenguaje, binary diffing y otras historias de “día uno”», el término «correlación» ha empezado a oírse con frecuencia en los últimos tiempos. Sin embargo, en algunas ocasiones no suelen ser acertadas las aproximaciones, definiciones o referencias del término, o incluso desarrollos de software que dicen realizar estos cálculos. Un ejemplo en seguridad es el caso de algunas herramientas SIEM o similares, cuando se comenta que realizan correlaciones, cuando en ocasiones ejecutan en realidad otro tipo de técnicas de análisis. Estas herramientas suelen tener módulos de ejecución de consultas, bien en SQL, en un lenguaje propio de la herramienta, o incluso en pseudocódigo, pero que pueden no realizar ningún análisis ni cálculo de correlación.
¿Qué es?
Es una técnica de análisis de información con base estadística y, por ende, matemática. Consiste en analizar la relación entre, al menos, dos variables - p.e. dos campos de una base de datos o de un log o raw data-. El resultado debe mostrar la fuerza y el sentido de la relación.
Para analizar la relación entre variables se utilizan los llamados «coeficientes de correlación». Se realizan sobre sobre variables cuantitativas o cualitativas. Ello determinará si se calcula o bien el coeficiente de correlación de Pearson, el de Spearman, o el de Kendall. Esto si estamos hablando de correlaciones bivariadas. Existen otras como pueden ser las correlaciones o las medidas de distancia o disimilaridad de intervalos, recuentos o binarias (p.e. distancia euclídea, euclídea al cuadrado, Chebyshev, Bloque, Minkovsky, etc.)
Es una técnica ampliamente documentada, con múltiples fuentes de información abiertas para que cualquiera pueda acceder a sus principios y realizar sus propios análisis.
Hasta el momento la aplicación de la correlación ha sido amplia y diversa en diferentes campos como ciencias naturales, economía, psicología, etc. y por supuesto, en investigaciones de todo tipo. En lo que se refiere al campo de la seguridad de la información los fundamentos son los mismos, aunque por el momento aún se está desarrollando.
Fundamentos matemáticos de la correlación:
Analizaremos el caso más típico de dos variables cuantitativas. La relación puede ser de tipo lineal, polinómica, logarítmica, etc. Para ello se utiliza el Método de Mínimos Cuadrados. Consiste en minimizar el error de la relación calculada frente al hecho real, es decir, minimizar la desviación típica de los residuos de la regresión (Error Cuadrático Medio).
![]()
Siendo: ei la diferencia para cada elemento entre la observación real y el dato estimado ![]() , y n el número de elementos observados.
, y n el número de elementos observados.
De ahí, aplicando un ajuste lineal,
![]()
En el caso más simple: con una variable dependiente y otra independiente tendríamos
![]()
De esta surge el Coeficiente de Correlación de Pearson, el más conocido de los coeficientes de correlación:
![]()
Siendo: σxy la covarianza de las variables X e Y,σx la desviación típica de la variable X,
y σy la desviación típica de la variable Y.
Los valores que puede tomar R son: -1≤R≤1
- R=1: existe una relación positiva perfecta.
También se pueden valer de los siguientes rangos:
- R=-1: existe una relación negativa perfecta.
- -1<R<-0,5: existe relación negativa fuerte.
- R=-0,5: existe una relación negativa moderada.
- -0,5<R<0: existe relación negativa débil.
- R=0: no existe relación, no existe relación lineal, Y no depende linealmente de X.
- 0<R<0,5: existe relación positiva débil.
- R=0,5: existe una relación positiva moderada.
- 0,5<R<1: existe relación positiva fuerte.
- R=1: existe una relación positiva perfecta.
Para analizar la relación entre variables existen múltiples métodos, ejemplos de ellos son:
- Regresión Lineal.
- Regresión No Lineal.
- Regresión Logística.
- Modelos Probit.
- Tablas de Contingencia.
- Modelos Logarítmicos.
Ejemplos de fuentes de Información con explicaciones sobre la correlación:
- [MIT]: Correlation and Regression
- [MIT]: Correlation and Regression (2)
- [MIT]: Regression Analysis: Method of Least Squares
- [MIT]: Correlation Analysis
- [MIT]: Tests for the Regression Equation
- [MIT]: Probabilistic Systems Analysis and Applied Probability, Derived distributions, convolution; covariance and correlation
- [RAE]: Correlación
- [UOC]: Regresión Lineal
- [WIKIPEDIA]: Correlation and dependence
¿Qué se necesita para realizar una correlación?, ¿cuáles son los requisitos mínimos?:
Conocer los datos y la tipología de las variables: bien de tipo cuantitativo o cualitativo. Dado que en función del tipo de las variables del conjunto de datos, se aplicarán una serie de coeficientes u otros.
Conocer qué método es el más adecuado para su aplicación: de nada vale conocer el script que ejecuta una correlación, si no se puede basar matemáticamente cómo desarrollar los cálculos.
Conocer, comprender e interpretar los resultados que los indicadores ofrecen: parte fundamental del análisis, basada en la diferencia existente entre los conceptos de causalidad y correlación que subyace en el análisis, y que suelen confundirse. El mero cálculo de un coeficiente, no determinado por una causalidad, no tiene porqué ser válido. Es decir «la existencia de correlación, no implica causalidad», como se refleja en esta viñeta:
- Lo primero, un «conjunto de datos».
- En dicho conjunto el requisito es tener mínimo dos «variables» (éste es el nombre técnico), según unas técnicas u otras se han denominado «dominios», «campos» de una base de datos y similares.
- Conocer las bases matemáticas y estadísticas del análisis de datos, en concreto:

¿Qué no es una correlación?, ejemplos:
1. Un análisis de frecuencias:
Hacer una cuenta, lo que técnicamente se denominan «frecuencias ordinarias o acumuladas» y «absolutas o relativas». Que en su modo multidimensional se completan con las «frecuencias marginales y condicionales». Este es el caso más habitual, reflejado en la típica instrucción SQL o Python cuyo resultado es un agregado COUNT o SUM.
Un ejemplo práctico de lo que no es una correlación en seguridad: es contar el número de direcciones IP bloqueadas por un determinado filtro dentro de una base de datos o log de sistemas, cuando el número de conexiones hacia una «network destination address» concreta sobrepasa un umbral máximo establecido desde una determinada localización («source address» o geográfica). Esto no es una correlación, es un mero análisis de frecuencias, en este caso absolutas ordinarias y condicionales -por lo multidimensional-, estableciendo un límite de aparición. El límite no es más que un cuantil -de ellos los más usados son los percentiles... los mismos que usa el pediatra -, calculado sobre la frecuencia condicional.
2. Realizar un gráfico, como el típico «histograma de frecuencias» o gráfico de tarta con unos porcentajes o valores absolutos. Tampoco lo son lo que en la actualidad se denominan «Visual Representations». En general estas herramientas facilitan la representación de un resultado, mejorando su comprensión, pero no tienen por qué hacer referencia a un análisis de correlación. De hecho el primer gráfico que se suele realizar para el análisis de correlación, dependiendo del número de variables, p.e. en el caso de dos variables, es un «diagrama de dispersión». Aunque realizar este diagrama no es una correlación, es el primer paso para conocer la posible existencia de relación o independencia entre las variables.
Suele ser común que el analista prefiera una tabla de datos de resultados sencilla, y en ella encuentra todo lo necesario para tomar decisiones, dado que ésta será la que alimente el gráfico, que habitualmente será el presentado a terceros.
3. La estadística nos proporciona otras herramientas más adecuadas. Un ejemplo de ello es contrastar la frecuencia temporal de envío de spam desde una determinada IP en un período, y analizar si su distribución -estadística, no geográfica- en función de un determinado parámetro, se ha modificado, y determinar si el establecimiento de un filtro ha funcionado o es necesario modificarlo, cambiarlo o eliminarlo. Esto no se realiza mediante una correlación, existe una técnica más apropiada denominada «Contraste de hipótesis», de la que hablaremos otro día, y de la que veremos casos reales explotando datos de un SIEM. De esta técnica surgen conceptos también ampliamente utilizados como «Falso positivo» o «Falso negativo» ... cualquier administrador de un servidor de correo electrónico da fe de lo costoso que es aplicar dicha técnica para poder parametrizar las reglas que definen unos y otros, y que dichos filtros funcionen correctamente ... que nunca perfectamente.
Herramientas y software para realizar análisis de datos y correlaciones:
Una correlación no es más que una técnica de las distintas que existen para realizar análisis de datos e información. Para analizar datos las herramientas más utilizadas son:
- Desde la siempre más sencilla hoja de papel y lápiz, y con una calculadora al lado para ayudarnos ;-)
- Cuando el conjunto de datos contiene un número de registros elevado, o se convierte en un modelo multidimensional, es cuando lo más eficiente es utilizar software, sin olvidarnos que no vale de nada conocer las instrucciones, si no conocemos los datos, tipología, y la base matemática que desarrolla los cálculos, ni somos capaces de comprender o interpretar los resultados que los indicadores nos dan.
En la actualidad existen multitud de herramientas para realizar este tipo de análisis de datos:
- Hojas de cálculo: para conjuntos de datos pequeños, aunque no preparadas exactamente para ello, si no para usos más generalistas, y que adolecen por su campo de datos finito.
- R: Lenguaje de programación interpretado para análisis estadístico y gráfico, con módulos GUI como R-Commander (Proyecto R).
- SPSS: software de análisis de IBM, con su propio lenguaje interpretado. (SPSS)
- SAS: "statistical analysis systems" software de análisis con lenguaje interpretado de la empresas de mismo nombre. (SAS)
- Python: no es realmente una herramienta, es un lenguaje de programación interpretado, pero por su difusión actual se están diseñando librerías de análisis de datos en él, además de que, por su versatilidad, se puede integrar en procesos de las herramientas anteriores. A su vez esto es una pequeña desventaja, dado que como lenguaje está pensado para uso generalista no técnico para análisis de datos. (Python)
- Otras: por ejemplo Matlab, Stata, etc. Existe una multitud de herramientas e información al respecto, en los siguientes enlaces se proporciona un listado exhaustivo de ellas y de comparativas por características técnicas e, incluso, demanda de empleo.
The Popularity of Data Analysis Software
Which Big Data, Data Mining, and Data Science Tools go together?
Ventajas: entre las más importantes para elegir una herramienta u otra, podemos destacar:
- La posibilidad de tener prediseñados los módulos de cálculos de la mayor parte de los análisis que se puedan realizar, desde sencillos cálculos de frecuencias, a todo tipo de análisis multidimensional o de series temporales.
- Algunas de ellas -la mayoría de las que hemos referido- tienen su propio lenguaje interpretado, lo que permite personalizar el análisis y automatizar tareas, cálculos y análisis. Esto es fundamental en procesos continuos de cálculo, además de las ventajas típicas de utilización de scripts versus utilizar GUI.
- En algunas de ellas pueden embeberse procesos o librerías de otras herramientas, como por ejemplo puede utilizarse Python dentro de R y SPSS.
¿Cuál es la mejor? Dependerá del científico de datos el determinar qué herramienta usar. Como siempre ha ocurrido, en el universo del software, cada una tiene sus ventajas e inconvenientes. Entre las de código abierto hay múltiples comparativas, y como al final se comenta allí la mejor... «Depende de ti».
El tamaño del conjunto de datos -número de registros y variables-, la posibilidad de disponer de un lenguaje interpretado, si es open source o no, requerimientos de hardware, son sólo algunas de las características que se deben tener en cuenta para seleccionar una u otra.
Ejemplos de Scripts que realizan correlaciones (desgranando los comandos uno a uno):
En R:
- Cargamos los datos desde un archivo de texto, con dos variables, separados los datos por tabulaciones:
![]()
- Ejecutamos el cálculo de la correlación, que calcula el coeficiente de correlación de Pearson:
![]()
En SPSS:
- Cargamos los datos desde un archivo sav:
![]()
- o bien cargamos los datos desde un archivo de texto, con dos variables, separados los datos por tabulaciones:
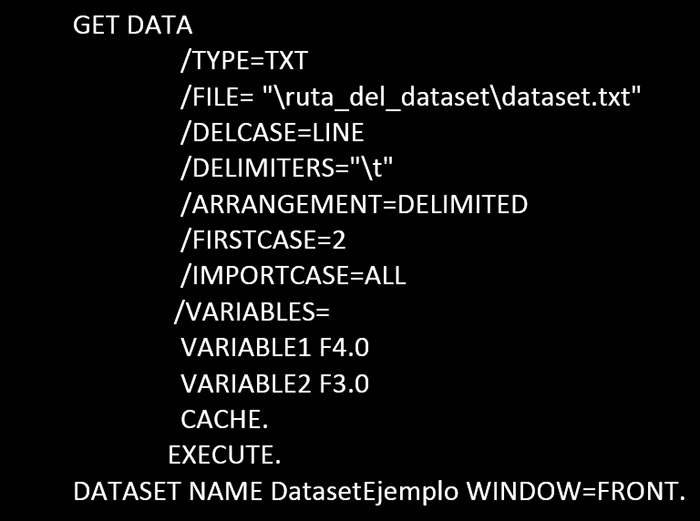
- Ejecutamos el cálculo de la correlación, que calcula el coeficiente de correlación de Pearson:

- Y tras realizar los cálculos se deben interpretar los resultados, como anteriormente comentamos en este mismo post.
Ejemplos de scripts que no son una correlación:
En cualquier lenguaje o aplicación son todos aquellos cuya estructura final de consulta resida sobre un COUNT o un SUM o un agregado de ellos, dado que esto no es más que un cálculo de frecuencias:
En SQL
![]()
En Python:
![]()
... y ¿qué conocimientos se necesitan para poder realizar un análisis de datos y una correlación utilizando datos de seguridad? Existen listados que recomiendan tener habilidades en materias u otras, en general: matemáticas -y su «hermana pequeña» la estadística-, conocimientos de seguridad de la información, informática, bases de datos, software de cálculo, lenguajes de análisis y consultas (R, SPSS; SQL, Python), técnicas de normalización, depuración y análisis de datos, ... y disponer de verdad de un equipo multidisciplinar que comparta dichos conocimientos, sin el cual esta entrada de blog, y otras futuras, no habrían sido posibles.
En próximas entradas presentaremos ejemplos reales de análisis de correlaciones y contrastes de hipótesis sobre datos de seguridad recogidos en un SIEM, haciendo un análisis que tenga el cálculo y el contraste de validez sobre el parámetro de la correlación…para que no nos suceda lo siguiente:
- Bob: ¡Qué maravilla, tras toda la noche dándole vueltas y calculando, ya lo tengo: he obtenido un coeficiente de correlación de Pearson de 0,98!
- Alice: Anda deja eso y baja a desayunar... acabas de demostrar que a los niños los trae la cigüeña de París.
(nota: las variables que utilizó Bob fueron las poblaciones de cigüeñas, el número de nacimientos de niños, y número de iglesias (cigüeñas en ellas) en una determinada localización).





